Image classification
by Federico Magliani
Uno dei problemi più diffusi e affrontati nell’ambito dell’intelligenza artificiale applicata alle immagini è quello dell’image classification (classificazione delle immagini in categorie).
Di cosa si tratta?
Dato un dataset di immagini suddiviso per categorie, il compito del modello di IA sarà quello di classificare correttamente le immagini senza mai averle viste, ma dopo aver appreso come riconoscere una classe dall’altra.
Problema
Nel caso di esempio che voglio illustrarvi in questo post ho generato un dataset artificiale composto da (3600) immagini di 3 differenti classi: cerchio, quadrato e rettangolo.
Le immagini rappresentano le varie forme di dimensioni differenti e traslate nell’immagine in modo casuale. Questa strategia serve per generare un dataset che rispecchi le condizioni reali di un caso di studio e per insegnare all’algoritmo a riconoscere la forma in varie posizioni.



Il dataset è stato suddiviso in train set (3000 immagini - 83%) e test set (600 immagini - 17%). È sempre importante che il modello di machine learning abbia dati a disposizione su cui allenarsi.
La maggior parte degli insuccessi in campo IA sono dovuti alla mancanza di dati. Spesso quindi IA e big data sono correlati, perché solo con tanti dati certi tipi di problemi riescono ad essere affrontati e risolti in maniera efficace.
Ci sarebbe poi da discutere sul tipo di dati disponibili e sulla loro qualità.
La qualità dei dati è importante per rendere più robusto il modello di intelligenza artificiale. È importante sapere che etichettare i dati richiede un lavoro accurato che aiuta ad incrementare la qualità dei dati ottenuti. Esiste, ad esempio, un servizio fornito da Amazon che permette di subappaltare l’attività di etichettatura dei dati ad un costo risibile per singola immagine.
CNN
Le reti neurali convoluzionali sono un’estensione delle reti neurali artificiali, in cui viene introdotto l’elemento convoluzione. Questo elemento è molto utile nell’ambito della visione artificiale. Permette, se utilizzato correttamente, di insegnare alla rete a riconoscere elementi nelle immagini (partendo da pochi pixel a pattern sempre più evoluti).
I neuroni sono inizialmente inizializzati con valori randomici, poi nel corso dell’allenamento del modello variano per adattarsi ai dati dei training.
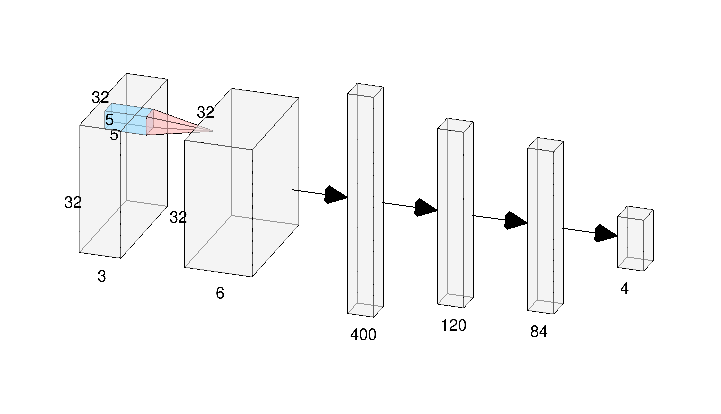
Come progettare la rete (i vari livelli) e il numero di neuroni?
In questo caso, la rete prevede due livelli in cui viene applicata la convoluzione; dopo la prima convoluzione viene applicato il max-pooling per ridurre la feature maps estratta dopo l’applicazione del primo filtro. Gli ultimi livelli sono fully-connected e sono reti neurali artificiali (introdotte nel post precedente). Nell’ultimo livello l’uscita è rappresentata da 4 neuroni.
Nota bene:
è stato introdotto il dropout (probability=0.1) negli ultimi livelli della rete neurale.
Per implementare la CNN ho utilizzato la libreria PyTorch.
La loss utilizzata è la cross entropy. L’andamento delle training e validation loss è riportato nel grafico seguente.

Dopo 6 epoche si può notare che la rete ha già imparato a discriminare e classificare le immagini. Successivamente la loss tende a salire quindi significa che la rete non sta continuando ad apprendere, anzi tende a dimenticare.
Risultati
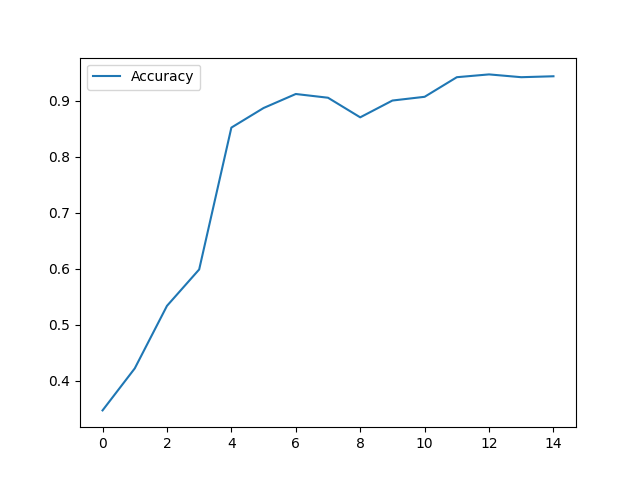
Ecco il grafico dell’accuracy sul test (deve essere calcolata SOLO sul test set). Come si può notare l’accuratezza del modello è di circa 94%, cioè vuol dire che in oltre 9 casi su 10 la rete riesce a distinguere un’immagine di un cerchio rispetto ad immagini contenenti quadrati o rettangoli.
Verso la sesta epoca si raggiunge un picco, che è in linea con l’andamento delle loss del grafico precedente.

Federico Magliani | Sono appassionato di Intelligenza Artificiale e nel 2020 ho ricevuto il Ph.D. in Visione Artificiale presso l'Università degli Studi di Parma.
Se vuoi ricevere maggiori informazioni sull'articolo o sui progetti che sto svolgendo visita il mio sito web. Privacy Policy |