Support Vector Machine
by Federico Magliani
Entriamo nel vivo dell’azione!
In questo post proverò quindi a presentare uno degli algoritmi più noti e diffusi di apprendimento automatico utilizzato per risolvere i problema di classificazione e regressione: il SVM (Support Vector Machine).
Definizione
“Utilizza i dati etichettati per definire un iperpiano con cui suddividere e classificare gli elementi presenti nel dataset.”
Che vuol dire?
Per spiegarvi meglio la definizione precedente voglio valutare il problema di classificazione binaria (ovvero fra due classi).
Ancora più nello specifico, consideriamo che siano solo 2 le features utilizzate per classificare le istanze del dataset. È quindi possibile rappresentare le istanze in un spazio cartesiano 2D.
L’algoritmo traccerà una retta (nel caso lineare) per suddividere le istanze delle due classi in base alla classe a cui appartengono. Questa retta servirà quindi per classificare le istanze non etichettate.
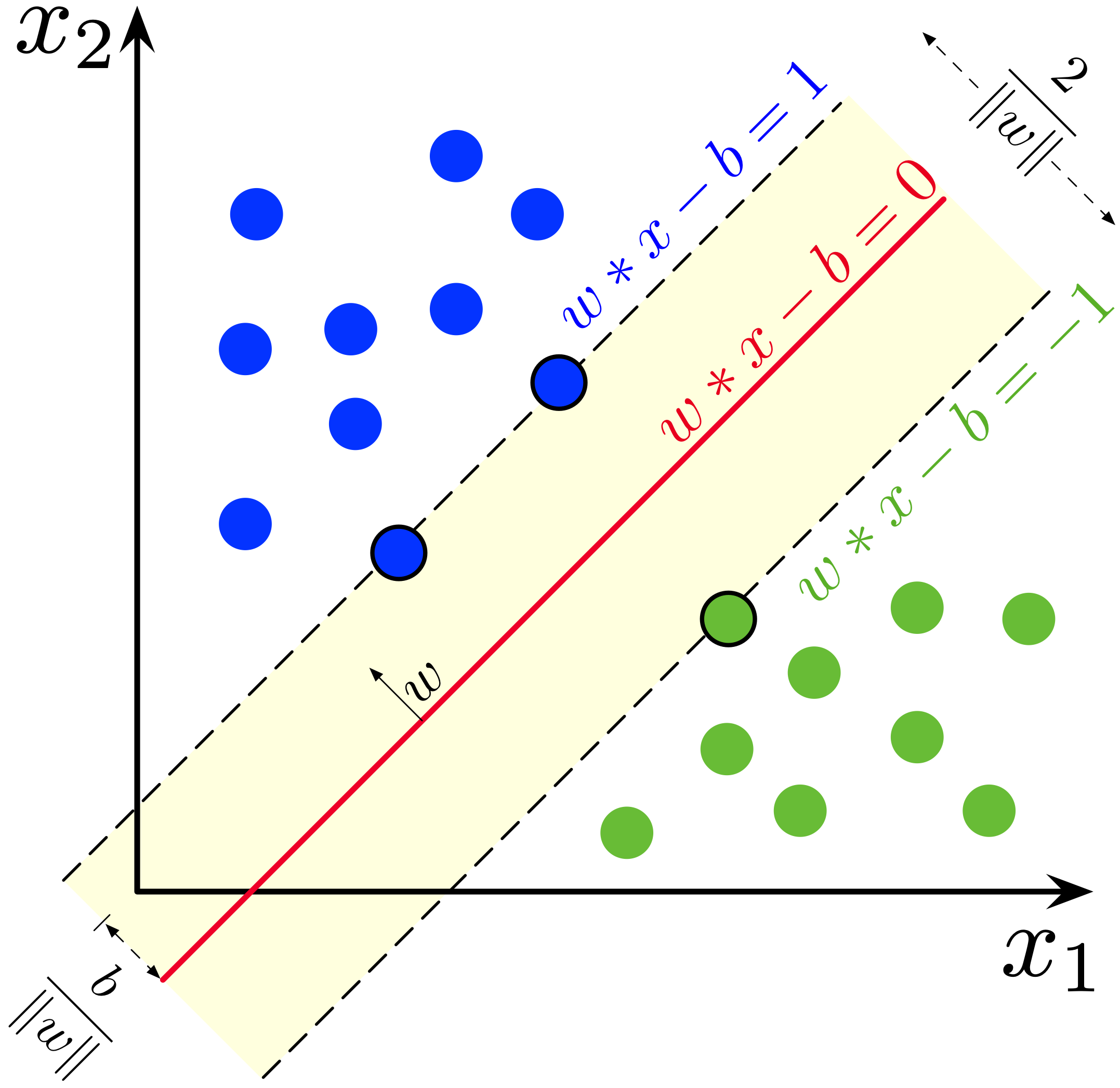
Figura 1 - Applicazione del SVM. Immagine sotto licenza CC BY-SA 4.0. Fonte: https://commons.wikimedia.org/wiki/File:SVM_margin.png
In Figura 1 sono riportate le istanze del dataset suddivise in base alle features scelte per la classificazione x1 e x2 . SVM definisce quindi una linea che suddivida equamente le istanze delle due classi. Nuovi elementi non etichettati saranno quindi classificati nella seguente maniera:
- se si troveranno al di sopra della linea rossa saranno classificati appartenenti alla classe blu;
- se si troveranno al di sotto della linea rossa saranno classificati appartenenti alla classe verde.
È importante notare che non sempre è possibile suddividere tutte le istanze del dataset nella maniera corretta come nel primo esempio presentato.
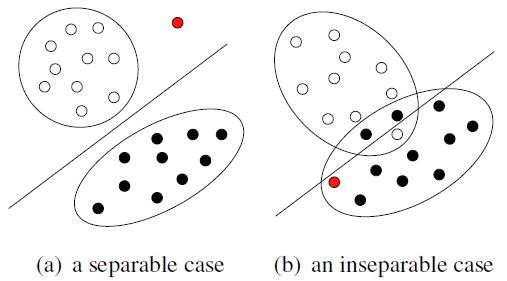
Figura 2 - Fallimento SVM. Immagine sotto licenza CC BY-SA 4.0. Fonte: https://commons.wikimedia.org/wiki/File:SVM_margin.png.
In Figura 2 viene mostrato come l’utilizzo di un kernel lineare non permetta di risolvere il problema. Probabilmente utilizzando un altro kernel si potrebbero ottenere risultati migliori. Non sempre ciò è possibile!
Prima di terminare voglio mostrare in Figura 3 l’utilizzo di SVM nel caso in cui vengano utilizzate 3 features per la classificazione. In questo caso anziché tracciare una retta, viene utilizzato un piano.
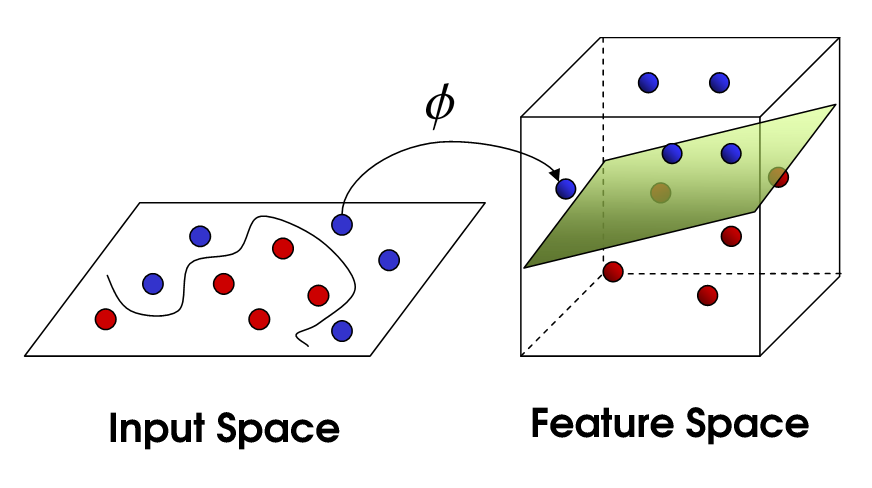
Figura 3 - SVM applicato su spazio 3D. Immagine sotto licenza CC BY-SA 4.0. Fonte: https://commons.wikimedia.org/wiki/File:Kernel_yontemi_ile_veriyi_daha_fazla_dimensiyonlu_uzaya_tasima_islemi.png.
In conclusione, il suddetto algoritmo è molto utilizzato perché efficiente ed efficace (ovvero produce buoni risultati di classificazione in tempi di computazione relativamente brevi) ed esistono varie implementazioni, tra cui vi consiglio la versione presente nella libreria sklearn.
Spoiler
Nel prossimo post presenterò un caso di studio relativo ad un semplice problema di classificazione, in cui utilizzerò SVM.

Federico Magliani | Sono appassionato di Intelligenza Artificiale e nel 2020 ho ricevuto il Ph.D. in Visione Artificiale presso l'Università degli Studi di Parma.
Se vuoi ricevere maggiori informazioni sull'articolo o sui progetti che sto svolgendo visita il mio sito web. Privacy Policy |