Tutti i dati sono uguali?
by Federico Magliani
NO! Lo vedremo meglio nel resto del post.
Perché dovrebbe interessarvi conoscere i dataset utilizzati in letteratura?
Innanzitutto per valutare la bontà del vostro modello di IA.
Come secondo punto, perché è possibile utilizzare questi dati come spunto di partenza per allenare il vostro modello. Vedremo meglio nei prossimi post quali sono le tecniche più note di apprendimento automatico e come si fa realmente ad allenare un modello di IA.
È risaputo che nel mondo dell’IA la maggior parte del lavoro del data scientist consista nel trovare i dati, pulirli e cercare di crearci valore.
La fase di pulizia o pre-processing dei dati è quindi molto importante. Consiste nella eliminazione o semplicemente riduzione del rumore presente nelle informazioni del dataset.
Tutto ciò può essere declinato anche nell’esecuzione di operazioni di preparazione dei dati per via di dati doppi, mancanti, inconsistenti o non necessari.
Nota bene:
Per rumore si intende la presenza di caratteristiche (features) che non aiutano nella risoluzione del problema, anzi infastidiscono il data scientist nella risoluzione dello stesso.
Un esempio di rumore nei dati?
Ad esempio nelle immagini la presenza di distrattori come lo sfondo o altri oggetti che non sono rilevanti ai fini del problema.
In ambito testuale la presenza di caratteri non correttamente interpretati come le lettere accentate può determinare problemi.
Alcuni fra gli algoritmi più noti per il pre-processing dei dati sono i seguenti:
- normalizzazione dei dati → significa che tutti i dati vengono scalati rispetto ad uno stesso metro di giudizio per evitare che alcuni di essi abbiano un maggiore peso. Ad esempio in un problema di regressione, la variabilità delle features analizzate potrebbe influenzare il modello creato, ma se esse sono normalizzate allora il modello sarà molto più realistico.
La mean normalization è probabilmente la tecnica di normalizzazione più diffusa e consiste nel normalizzare i dati rispetto alla media di tutti i dati presenti. Matematicamente parlando funziona così: x’ = (x – avg(x)) / (max(x) – min(x)). Per approfondire altre tecniche di normalizzazione vi invito a visitare la relativa pagina di Wikipedia; - analisi delle componenti principali (PCA) → tecnica che viene utilizzata per eliminare le informazioni ridondanti e ridurre la complessità computazionale dell’algoritmo necessario per risolvere il problema. Viene applicata quando le informazioni presenti nel dataset non possono essere rappresentate in un grafico cartesiano 2D o 3D.
Riducendone la dimensione sarà poi possibile visualizzarli.
Applicare questo metodo comporta una riduzione del contenuto informativo, ma aumenta la capacità di comprensione e dovrebbe alleviare la presenza di rumore nel proprio dataset. Per maggiori dettagli vi invito a visitare la relativa pagina di Wikipedia oppure a leggere questo interessante articolo in cui vengono presentati vari metodi per la riduzione della dimensionalità dei dati.
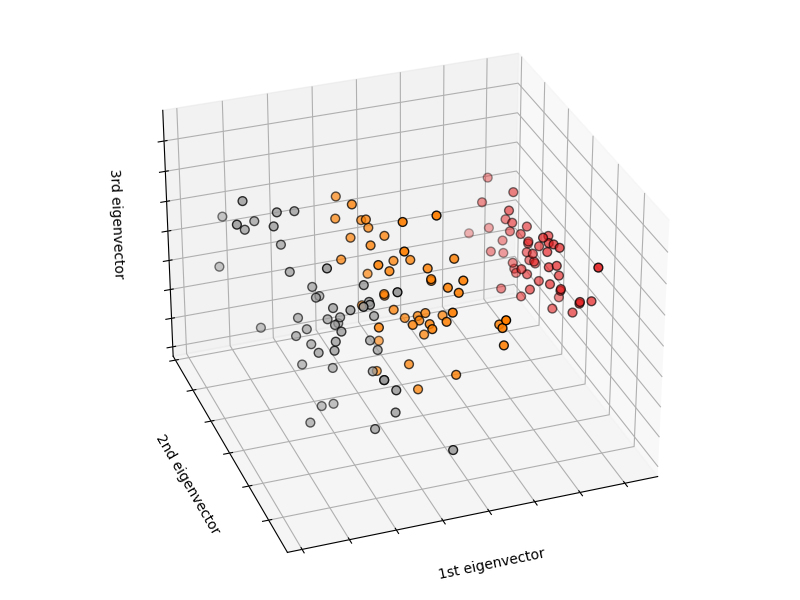
Figura 1 - Applicazione della PCA su IRIS dataset. Nell'IRIS dataset vengono riportate 4 features (lunghezza/larghezza petalo, lunghezza/larghezza sepalo). Nel grafico sono riportati i 3 principali autovettori estratti tramite l'applicazione del PCA sull'intero dataset.
Come si può notare in figura 1, semplicemente utilizzando il primo autovettore (1st eigenvector) è possibile suddividere in maniera grossolana le classi e quindi cercare di classificare correttamente le istanze delle varie classi di IRIS.
È importante sottolineare che non sempre sia necessario applicare tecniche di pre-processing dei dati. Dipende dai dati a disposizione.
Esistono anche altri metodi per la pulizia dei dati che dipendono dal problema in esame. Per esempio nella valutazione dei sentimenti (sentiment analysis) è comune applicare tecniche per semplificare la frase in input, ad esempio sostituire nella frase tutte le forme verbali comprendenti una negazione con un singolo tag NOT.
Questo stratagemma aiuta nella corretta valutazione del significato della frase, visto che il problema dell’ironia nell’interpretazione dei testi è molto comune.
Dopo aver pulito i propri dati, un buon data scientist deve capire quali siano le corrette features da utilizzare nella risoluzione del problema. I metodi di ML non definiscono le features da utilizzare, ma solo la metodologia da utilizzare.
Sarà l’esperienza del data scientist ad intervenire nella scelta delle features da utilizzare. Non preoccupatevi, di questo argomento ne parleremo a brevissimo.
Spoiler
Nel prossimo post inizierò a presentare i più famosi metodi di apprendimento automatico per la classificazione.

Federico Magliani | Sono appassionato di Intelligenza Artificiale e nel 2020 ho ricevuto il Ph.D. in Visione Artificiale presso l'Università degli Studi di Parma.
Se vuoi ricevere maggiori informazioni sull'articolo o sui progetti che sto svolgendo visita il mio sito web. Privacy Policy |